
How Self-Correction in Large Language Models Can Be Improved
A Deep Dive into "SCoRe" (From a Research Paper That I Liked in September 2024)

We know that in recent times, large language models (LLMs) have completely changed how we interact with technology, enabling applications in natural language processing, coding, and reasoning.
However, one significant challenge remains the ability of these models to self-correct their mistakes.
This article explores a groundbreaking approach called SCoRe (Self-Correction via Multi-Turn Reinforcement Learning), which enhances the self-correction capabilities of LLMs.
We will break down the key concepts, findings, and implications of this research in a simplified manner. If you want to read the full paper, here is the research paper.
What is Self-Correction in LLMs?
Self-correction refers to the ability of a model to identify and rectify its errors during the response generation process. This capability is crucial for tasks that require reasoning, such as solving mathematical problems or writing code.
Traditional LLMs often struggle with self-correction, especially when they lack external feedback or guidance.
This is how a standard LLM is trained.
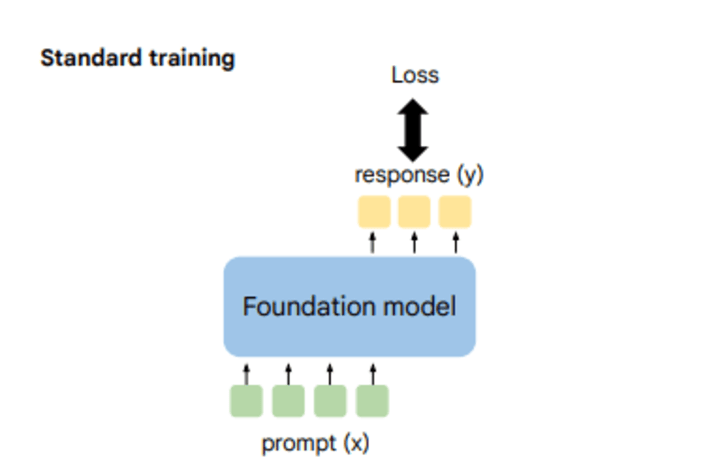
This limitation can lead to incorrect or suboptimal responses, which is a significant hurdle in deploying these models in real-world applications.
🗞 Ad: Introducing My Paid Newsletter
If you are interested in reading AI research papers in the most simplified way like this article, and also want to receive a collection of well-crafted prompts:
AI Made Simple: Research Papers & Prompt Collection
Unlock the latest in AI with simple explanations and powerful prompts every week.
The SCoRe Approach
Overview of SCoRe
SCorE introduces a method for teaching LLMs to self-correct using a multi-turn reinforcement learning (RL) framework.
Unlike previous approaches that relied on supervised fine-tuning (SFT) or external feedback, SCoRe trains models using only self-generated data.
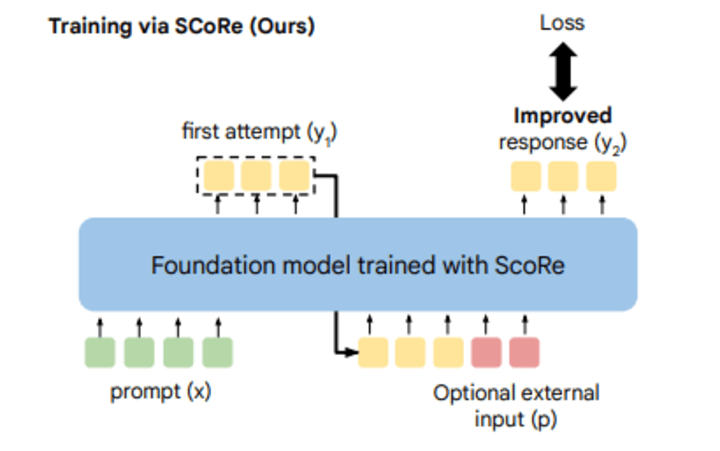
This means that the model learns to improve its responses based on its outputs, making it more autonomous and adaptable.
Key Components of SCoRe
1. Reinforcement Learning:
SCoRe employs a reinforcement learning strategy, where the model learns through trial and error.
It receives rewards for making correct corrections and penalties for incorrect ones.
This feedback loop helps the model refine its self-correction abilities over time.
2. Self-Generated Data:
One of the most innovative aspects of SCoRe is its reliance on self-generated data for training.
The model learns from its own mistakes without needing external supervision, which is particularly beneficial in scenarios where external feedback is unavailable.
3. Multi-Turn Training:
The approach involves multiple rounds of interaction, allowing the model to generate a response, evaluate it, and then correct it if necessary.
This iterative process mimics how humans often revise their work, leading to more accurate outcomes.
Working: The Two-Stage Training Process
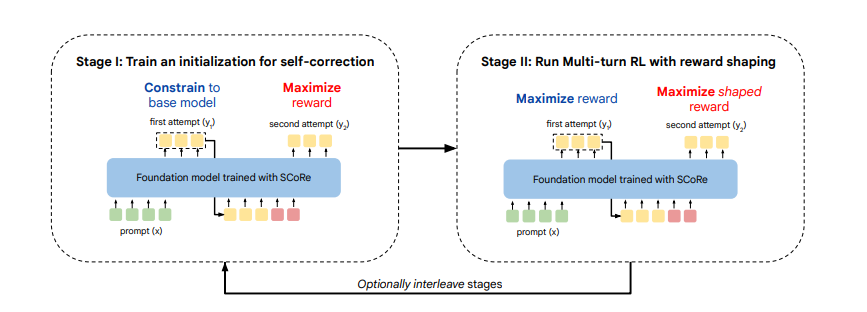
SCorE employs a two-stage training process to enhance its effectiveness:
Stage 1: Policy Initialization
In the first stage, the model is trained to generate a strong initial response. This phase focuses on creating a baseline that is less prone to errors, setting the stage for effective self-correction.
Stage 2: Reward Shaping
In the second stage, the model is fine-tuned using a reward system that encourages self-correction. By providing positive reinforcement for successful corrections, the model learns to prioritize improving its responses.
Key Findings from the Research
1. Significant Performance Gains:
The implementation of SCoRe led to substantial improvements in self-correction capabilities.
The model achieved a 15.6% improvement on the MATH benchmark and a 9.1% improvement on the HumanEval coding benchmark compared to baseline models.
This demonstrates the effectiveness of the SCoRe approach in enhancing LLM performance.
2. Qualitative Improvements:
The research included qualitative analyses that showed how SCoRe enables models to refine their responses.
For instance, the model could rewrite entire solutions or selectively correct parts of its answers, showcasing a nuanced understanding of its mistakes.
3. Addressing Limitations of Previous Methods:
The authors highlighted the shortcomings of existing self-correction methods, particularly those relying on supervised fine-tuning.
SCoRe effectively addresses these issues by avoiding distribution mismatches and promoting a more effective self-correction strategy.
Practical Applications of SCoRe
The advancements made through SCoRe have several practical applications:
Educational Tools: SCoRe can be integrated into educational platforms to create intelligent tutoring systems that provide real-time feedback and corrections to students, enhancing their learning experience.
Automated Code Review: In software development, SCoRe can be used to develop tools that automatically review and correct code submissions, improving the efficiency of the development process.
Interactive Assistants: Virtual assistants and chatbots can leverage SCoRe to enhance their ability to understand and correct user queries in real time, leading to more accurate and helpful interactions.
Content Generation: SCoRe can be applied in content creation to refine generated text, ensuring higher quality and coherence in writing.
Future Directions
While SCoRe represents a significant advancement in self-correction capabilities, there are still opportunities for further research and development:
Multi-Round Self-Correction: Future work could explore extending the SCoRe framework to allow for multiple rounds of self-correction, enabling models to iteratively refine their responses beyond the initial attempts.
Integration with External Feedback: Combining self-generated corrections with user feedback or expert evaluations could create a more robust learning environment.
Domain-Specific Adaptations: Adapting SCoRe for specific domains, such as legal reasoning or medical diagnosis, could improve its effectiveness in specialized applications.
Exploration of Different Reward Structures: Investigating various reward structures could provide insights into optimizing the learning process and enhancing the model's correction strategies.
Conclusion
The SCoRe approach marks a significant step forward, to enhance self-correction capabilities in large language models.
By leveraging reinforcement learning and self-generated data, SCoRe enables models to learn from their own mistakes, leading to improved performance in reasoning and coding tasks.
As researchers continue to explore and refine this approach, the potential applications and benefits of self-correcting LLMs will only grow, paving the way for more intelligent and capable AI systems in the future.
Connect: LinkedIn | Gumroad Shop | Medium | GitHub
Subscribe: Substack Newsletter | Appreciation Tip: Support